![]()
It has been a few months since OpenAI released its state-of-the-art Automatic Speech Recognition (ASR) model to the public, and the excitement surrounding it has not yet subsided. In my testing, the model's transcription quality, as measured by Word Error Rate (WER), is on par with other open-source ASR models, particularly those developed by Nvidia. It also appears to outperform its peers when it comes to transcribing long audio files. The only issue I have noticed is that the model may sometimes produce "hallucinations" in the transcription, particularly for longer audio files.
Unfortunately, Whisper does not provide the ability to identify the speaker for its transcriptions. They may add that ability in the future. Until then, we will try to come up with a solution that works well in most cases.
Along with text transcripts, Whisper also outputs the timestamps for utterances, which may not be accurate and can have a lead/lag of a few seconds. For accurate speaker diarization, we need to have correct timestamps for each word. Some clever folks have successfully tried to fix this with WhisperX and stable-ts. These libraries try to force-align the transcription with the audio file using phoneme-based ASR models like wav2vec2.0. If Whisper outputs hallucinations, these libraries may not function properly or could potentially break.
Once we get timestamps for each word, we need to find the mapping between timestamps and speaker labels. We can achieve this by using a diarization framework. A typical diarization pipeline involves the following steps:
- Voice Activity Detection (VAD) using a pre-trained model.
- Segmentation of audio file with a window size of 0.5-3s.
- Speaker embedding extraction of these segments using a pre-trained model.
- Clustering (Spectral, K-Means, or any other) the speaker embeddings to correctly label each segment with a speaker label.
Nearly all unsupervised Diarization frameworks follow the same approach. I have seen a lot of previous attempts to diarize whisper transcriptions using pyannote. The best one I saw so far involved getting timestamps for each speaker label using pyannote and using these timestamps to segment the audio file and feed each segmented audio file to Whisper. This approach works fine, but it can be pretty slow, especially if there are many short utterances in a long audio file.
I tried to use pyannote for my attempt at diarization, but it didn't give good results compared to Nvidia Nemo. It may be because of the way Nemo performs segmentation. For correct diarization results, we would prefer the window_length to be as fine as possible so that we can diarize utterances like yeah, hmm, and oh, etc. But a fine window_length will also make it hard to identify the speaker, as our sample size is also small. Similarly, a coarse window_length will give you enough sample to correctly identify the speaker, but you can't label precise utterances.
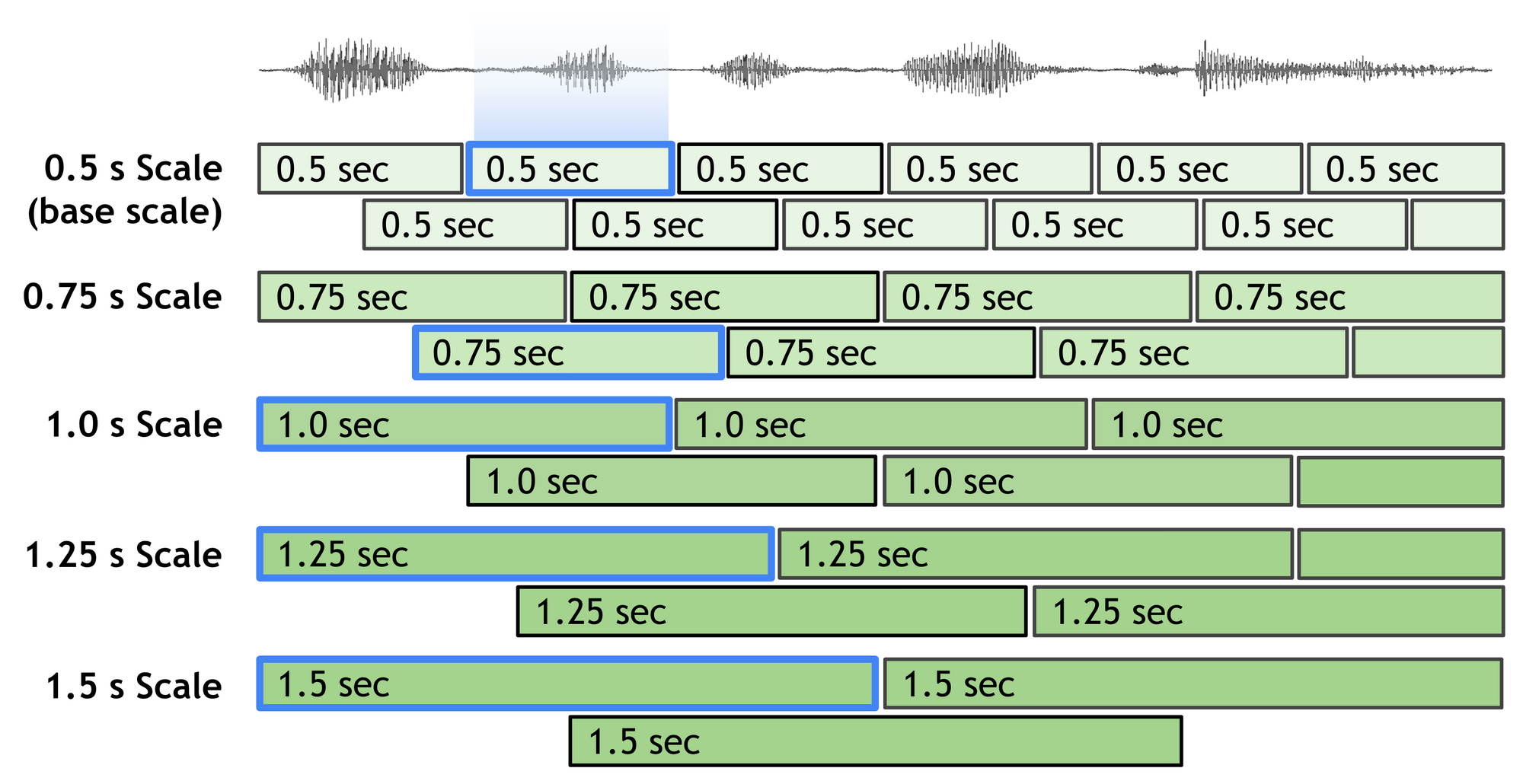
Nemo solves it by using multi-scale segmentation, i.e., we segment the audio file with different window lengths, e.g., [1.5s, 1.0s, 0.5s]. During the embedding extraction of the smallest window_length, i.e., 0.5s for our example, we also calculate embeddings for other scales (1.5s and 1.0s) which are closer to the smallest segment and take a weighted average of these embeddings before feeding them to the clustering algorithm.
Once we diarize the input audio file using Nemo's Clustering Diarizer, we get the mapping between timestamps and speaker labels. We can combine this mapping with whisperX's generated (word, timestamps) mapping to get (word, speaker label) mapping. We can then use (word, speaker label) mapping to get a fully diarized transcript, i.e., (Speaker Label: Sentences/Utterances). Our diarized transcript would still have some errors during speaker changes. You may see something like this:
Speaker A: It's got to come from somewhere else. Yeah, that one's also fun because you know the lows are
Speaker B: going to suck, right? So it's actually it hits you on both sides.
......
We can see that the sentence Yeah, that one's...suck, right? is part of both Speaker A and Speaker B's utterances. This could happen due to frequent overlapped speech, background noise, or faulty timestamps (either from ASR or the diarization model). There are a couple of ways to correct this alignment error:
Realignment using N-Gram/Masked Language Models
One simple way is to use an n-gram Language Model (KenLM) or a masked Language Model to calculate sentence perplexity (log probability). To do that, we'll get the last few words of Speaker A's utterance and the first few words of Speaker B's utterances, add \n at different places, and calculate the sentence perplexity. The optimal position of \n would be where the probability is maximum. Something like this:
Speaker A: That was an amazon
Speaker B: podcast. Oh yeah, I really enjoyed it.
perplexity_score: 1
Speaker A: That was an amazon podcast.
Speaker B: Oh yeah, I really enjoyed it.
perplexity_score: 5
Speaker A: That was an amazon podcast. Oh
Speaker B: yeah, I really enjoyed it.
perplexity_score: 3
Speaker A: That was an amazon podcast. Oh yeah.
Speaker B: I really enjoyed it.
perplexity_score: 4
Speaker A: That was an amazon podcast. Oh yeah. I
Speaker B: really enjoyed it.
perplexity_score: 1
.....
I tried this approach on multiple examples. The results were promising but not consistent.
Realignment using Punctuations
Another simple method (you can call it a hack) is to use punctuation markings. If a sentence is split between two different speakers, it can either be part of Speaker A's utterance or Speaker B's utterance. We can simply take the mode of speaker labels for each word in the sentence and use that speaker label for the whole sentence. Something like this:
Speaker A: It's got to come from somewhere else. Yeah, that one's also fun because you know the lows are
Speaker B: going to suck, right? So it's actually it hits you on both sides.
The sentence Yeah, that one's also...right? is mostly spoken by Speaker A, so it should be considered part of Speaker A's utterance.
The situation becomes more complex when one speaker is giving a monologue while other speakers are making occasional comments like Hmm, yeah, and exactly in the background. The Whisper model may not take these very fine utterances into account, but the Diarization Model (Nemo) may include them, leading to inconsistent results. Something like this:
Speaker A: It's got to come from somewhere
Speaker B: else. Yeah,
Speaker A: that one's also fun because you know the
Speaker C: lows are
Speaker A: going to suck, right?
So only Speaker A was speaking. Others' hmm, yeah were ignored by Whisper, but because the Diarization model was able to give us timestamps for them, we saw this inconsistent output. Fortunately, our punctuation-based realignment will fix that.
Some special cases are hard to fix, i.e., when we have an equal part of both sentences split between two Speakers. Something like:
Speaker A: Oh
Speaker B: Yeah.
Speaker A: Yeah
Speaker B: Exactly.
Unfortunately, our punctuation-based realignment algorithm can't fix these errors. We have to accept them as part of the diarization error. Our realignment algorithm will assign them to either of the speakers.
Although whisper will automatically punctuate its transcripts, it may end up in a no-punctuation loop occasionally, and you may not get any punctuation markings. To avoid that, we can restore whisper transcripts punctuation marking using a pre-trained model.
Thank you for reading, and I hope you found this useful. If you have any questions, you can email me.